既然聊到了ai,那么这个头图其实也是 ai 换脸得来的,也用 ai 的图片吧,毕竟自己拍的写真的存货已经不多了没了。而鉴于现在这个温度,的确是不像去拍外景,怕拍完了就冻死在外面了。
与哪吒一样,这个春节热度飙升的在 ai 领域无疑就是 deepseek 了。自己最开始接触 deepseek 也是因为超便宜的价格,所以在很早之前就在用这个东西里,各种聊天记录可以看到很多基础问题,但是给的答案嘛,个人感觉并没有比其他的 ai 高很多,可以使用 duckduckgo 的免费 ai 聚合:https://duckduckgo.com/?q=DuckDuckGo+AI+Chat&ia=chat&duckai=1。
在节前另外一次出圈,应该是雷军挖了 deepseek 的自然语言专家罗福莉。当时还大概看了下这个姐妹的研究内容和方向。
等到了过年的时候deepseek 就成了碾压 chatgpt 之类的存在,到处都是他的新闻和消息。为此也有一群人开始出来蹭热度,四分之一个世界过去了,这个变化并不大,从之前的 bbs 转到了短视频平台。各种所谓的红客、ddos 、华为之类的假新闻和消息开始到处转发,甚至连周鸿祎都要出来蹭一波热度,如果仔细看过年期间 deepseek 的前端人机验证工具其实用的 cf 的。

甚至所谓的这些官方媒体都无脑转发这些乱七八糟的假消息。
至于我为什么要现在提这个东西,是因为放假的时候同事说可以试试 deepseek 的合同解析功能,可以识别里面的各种信息。按照他发的图,看了下,大约的确是可以的,然而,问题的关键在于 deepseek 的 sdk 并没有实现相关文件上传的方法。
说到 sdk,这里不得不说的是,在 ai 领域的 sdk 开发中,终于避免了重复造轮子的问题。多数都是 openai sdk 兼容的,只需要替换服务器地址和密钥即可。
DeepSeek API 使用与 OpenAI 兼容的 API 格式,通过修改配置,您可以使用 OpenAI SDK 来访问 DeepSeek API,或使用与 OpenAI API 兼容的软件。
PARAM VALUE base_url * https://api.deepseek.comapi_key apply for an API key
* 出于与 OpenAI 兼容考虑,您也可以将
base_url设置为https://api.deepseek.com/v1来使用,但注意,此处v1与模型版本无关。*
deepseek-chat模型已全面升级为 DeepSeek-V3,接口不变。 通过指定model='deepseek-chat'即可调用 DeepSeek-V3。*
deepseek-reasoner是 DeepSeek 最新推出的推理模型 DeepSeek-R1。通过指定model='deepseek-reasoner',即可调用 DeepSeek-R1。
以上是 deepseek 文档的内容,基于 openai sdk 的方法实现文件上传:
from openai import OpenAI
client = OpenAI(api_key=ak, base_url="https://api.deepseek.com")
response1 = client.files.create(file=open("../baidu_ocr_tools/test_data/contract.pdf", "rb"), purpose="batch")
执行后会得到下面的错误提示:
openai.NotFoundError: Error code: 404 - {'event_id': '30-inst-179-20250208132511-263a5c3c', 'error_msg': 'Not Found. Please check the configuration.'}y
也就是说 deepseek 没有实现文件上传的后端接口,但是聊天界面却是可以的。

既然 web 页面可以,那么就可以使用另外的方法:通过调用 web端的接口实现文件上传,要找接口也简单:
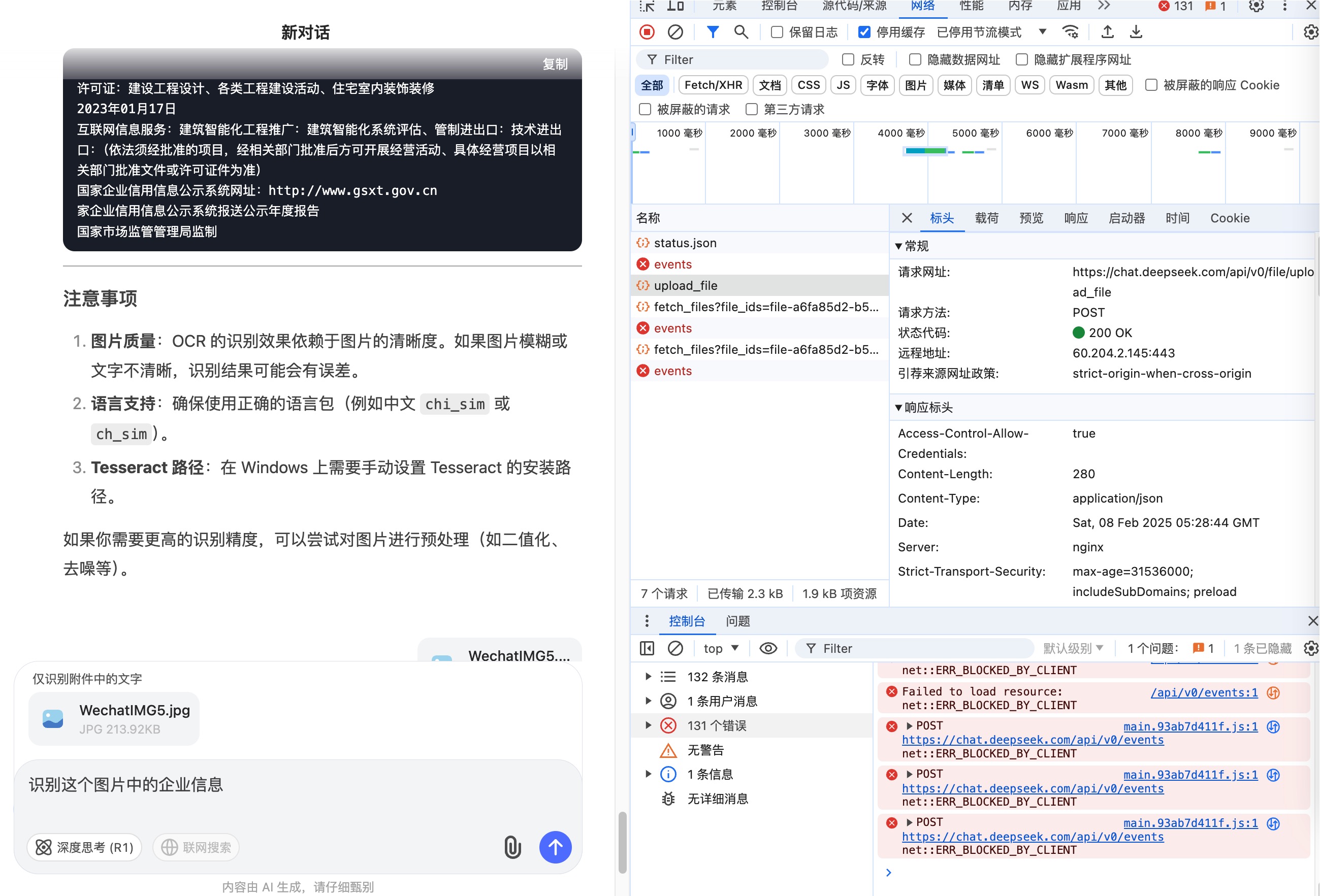
一个 upload 接口即可,然而,这个接口拿到之后,用相关的参数进行模拟,不管是代码提交还是 postman 提交,都得到了同样的错误,文件状态 pending,这个和 web 端一致:


然而获取文件信息的时候却是 failed,而 web 页面却是正常的:


同样的数据,重复提交也会失败,这就很神奇,当然,可能的问题出在header 中的x-ds-pow-response:
eyJhbGdvcml0aG0iOiJEZWVwU2Vla0hhc2hWMSIsImNoYWxsZW5nZSI6IjdmMThjNTQzMzZkNjM1YWFkODljOGMxZDE4YmMwNTk1M2MxZjY2N2ZhM2FiZDMyMmJiYTdhZDQwOWZhNDI5NzkiLCJzYWx0IjoiNzRhOWE1ZTdhM2YxNDU3NTdmNGUiLCJhbnN3ZXIiOjEyNjczMCwic2lnbmF0dXJlIjoiNWE3ZWQ1MzdjNjQ0OTY2Nzg3Yjk1Y2ZlNGU4NDc5YTAzYWYyMmFkNjA3MWMxMGU2YWQ3ZjZkZjAxMGM5NTZmMiIsInRhcmdldF9wYXRoIjoiL2FwaS92MC9maWxlL3VwbG9hZF9maWxlIn0
base64 decode后是:
{"algorithm":"DeepSeekHashV1","challenge":"7f18c54336d635aad89c8c1d18bc05953c1f667fa3abd322bba7ad409fa42979","salt":"74a9a5e7a3f145757f4e","answer":126730,"signature":"5a7ed537c644966787b95cfe4e8479a03af22ad6071c10e6ad7f6df010c956f2","target_path":"/api/v0/file/upload_file"}
算法写了DeepSeekHashV1,但是怎么实现的不知道,要去还原这个耗费太多精力,感觉不怎么值。另外 api 还有速率限制,所以可行性也不大高。
github 上有个代码也是基于 web 端的 api,
https://github.com/Cunninger/ocr-based-deepseek/blob/main/src/main/java/cn/yam/ocrbaseddeepseek/controller/OCRController.java
我没尝试,但是根据自己的经验,貌似行不通。
那么初次之外还有别的 ai 吗?
后来发现 kimi 的 api,同样是 opensdk 兼容的,并且实现了文件上传方法:
Kimi API 兼容了 OpenAI 的接口规范,你可以使用 OpenAI 提供的 Python(opens in a new tab) 或 NodeJS(opens in a new tab) SDK 来调用和使用 Kimi 大模型,这意味着如果你的应用和服务基于 openai 的模型进行开发,那么只需要将
base_url和api_key替换成 Kimi 大模型的配置,即可无缝将你的应用和服务迁移至使用 Kimi 大模型
示例代码测试:
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key = "sk-9naV7ApT*********",
base_url = "https://api.moonshot.cn/v1",
)
# xlnet.pdf 是一个示例文件, 我们支持 pdf, doc 以及图片等格式, 对于图片和 pdf 文件,提供 ocr 相关能力
file_object = client.files.create(file=Path("../baidu_ocr_tools/test_data/contract.pdf"), purpose="file-extract")
# 获取结果
# file_content = client.files.retrieve_content(file_id=file_object.id)
# 注意,之前 retrieve_content api 在最新版本标记了 warning, 可以用下面这行代替
# 如果是旧版本,可以用 retrieve_content
file_content = client.files.content(file_id=file_object.id).text
# 把它放进请求中
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。",
},
{
"role": "system",
"content": file_content,
},
{"role": "user", "content": "解析contract.pdf文件, 获取签订双方的信息,户号,公司名称等,解析的数据以 json 格式返回。"},
]
# 然后调用 chat-completion, 获取 Kimi 的回答
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
print(completion.choices[0].message)
执行结果:

这个结果自然还可以继续优化,或者调整提示词。但是最起码对于 openai sdk 的后端支撑是足够的。
这个世界毕竟是充满了人云亦云缺乏判断力的乌合之众,而稍微有点成绩很可能的结果就是被捧杀。稍微有点成绩就遥遥领先。
说实话,现在我看到遥遥领先这四个字都开始反胃了!
附,清华大学《deepseek 从入门到精通》: