Alec Radford has created some great animations comparing optimization algorithms SGD, Momentum, NAG, Adagrad, Adadelta, RMSprop (unfortunately no Adam) on low dimensional problems. Also check out his presentation on RNNs.
“Noisy moons: This is logistic regression on noisy moons dataset from sklearn which shows the smoothing effects of momentum based techniques (which also results in over shooting and correction). The error surface is visualized as an average over the whole dataset empirically, but the trajectories show the dynamics of minibatches on noisy data. The bottom chart is an accuracy plot.”
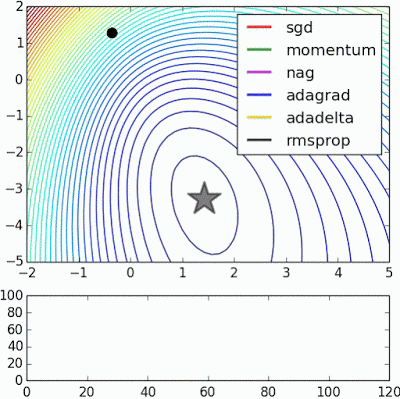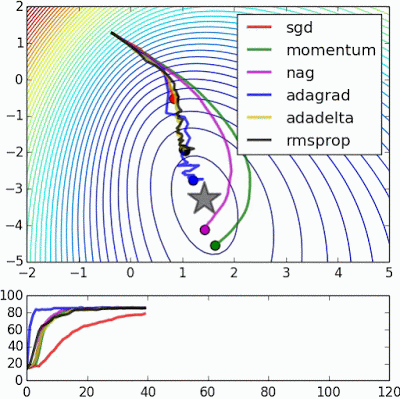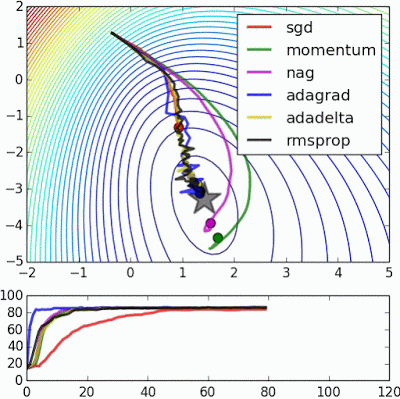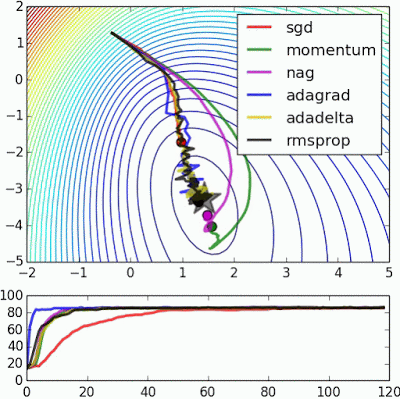
“Beale’s function: Due to the large initial gradient, velocity based techniques shoot off and bounce around – adagrad almost goes unstable for the same reason. Algos that scale gradients/step sizes like adadelta and RMSProp proceed more like accelerated SGD and handle large gradients with more stability.”
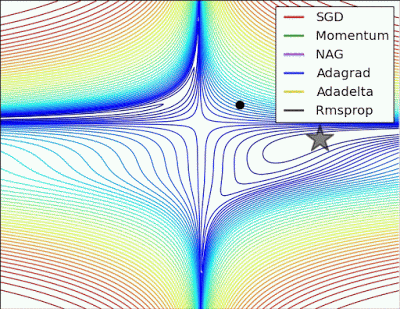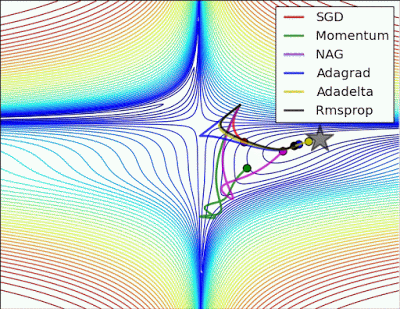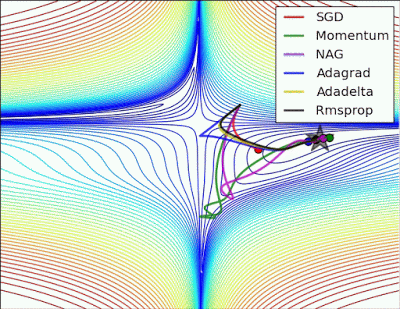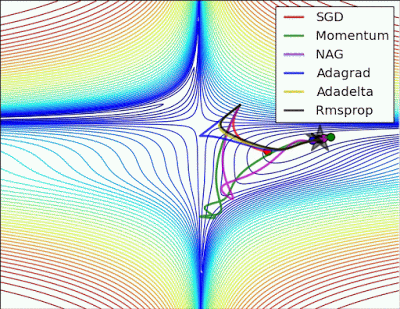
“Long valley: Algos without scaling based on gradient information really struggle to break symmetry here – SGD gets no where and Nesterov Accelerated Gradient / Momentum exhibits oscillations until they build up velocity in the optimization direction. Algos that scale step size based on the gradient quickly break symmetry and begin descent.”
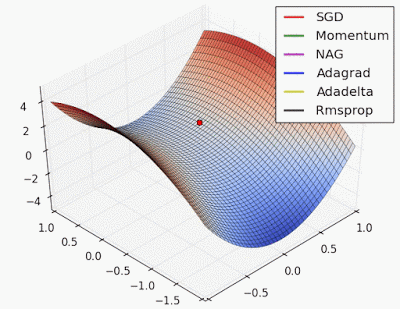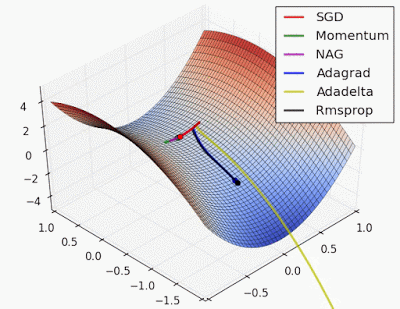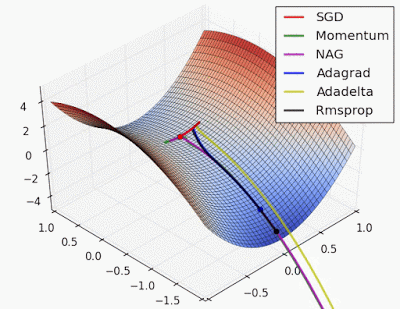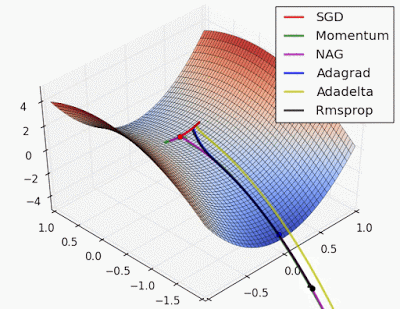
“Saddle point: Behavior around a saddle point. NAG/Momentum again like to explore around, almost taking a different path. Adadelta/Adagrad/RMSProp proceed like accelerated SGD.”
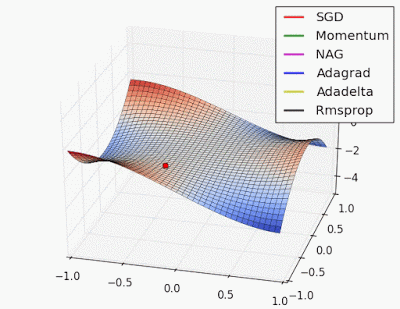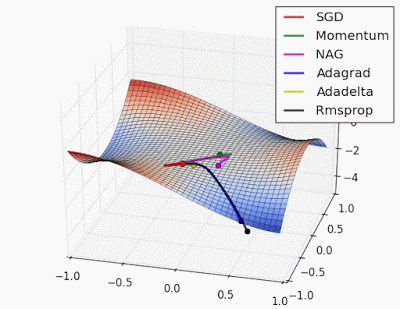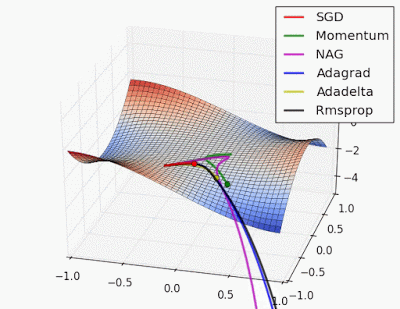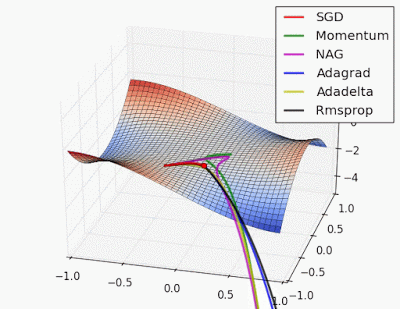
Source Link: http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html