
后台做数据分析汇总的时候需要处理各种时间段,每天的零点、每周的第一天最后一天、每月的第一天最后一天等,不知道有没有现成的可用库来处理。搜索的基本也是各种其他人写的方法,我这里汇总了一下(抄了一些代码)。
日期处理一般会用到下面几个库:time,datetime,calendar。一般通过这几个库来处理时间也够用了。
time 模块
该模块包括使用时间执行各种操作所需的所有与时间相关的功能,它还允许我们访问多种用途所需的时钟类型。
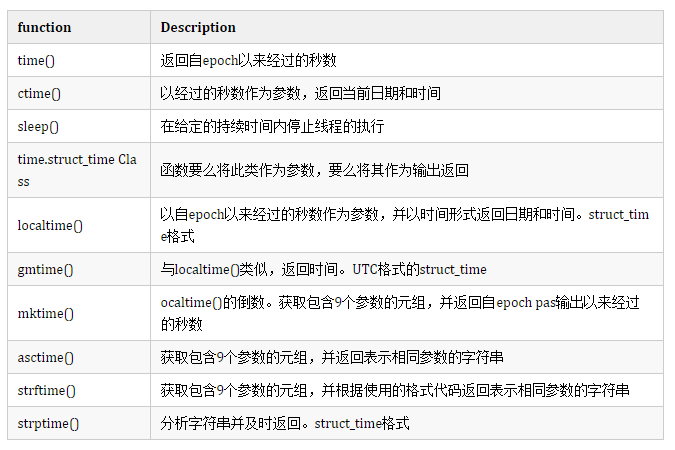
内置函数:
请看下表,它描述了时间模块的一些重要内置功能。
代码格式化:
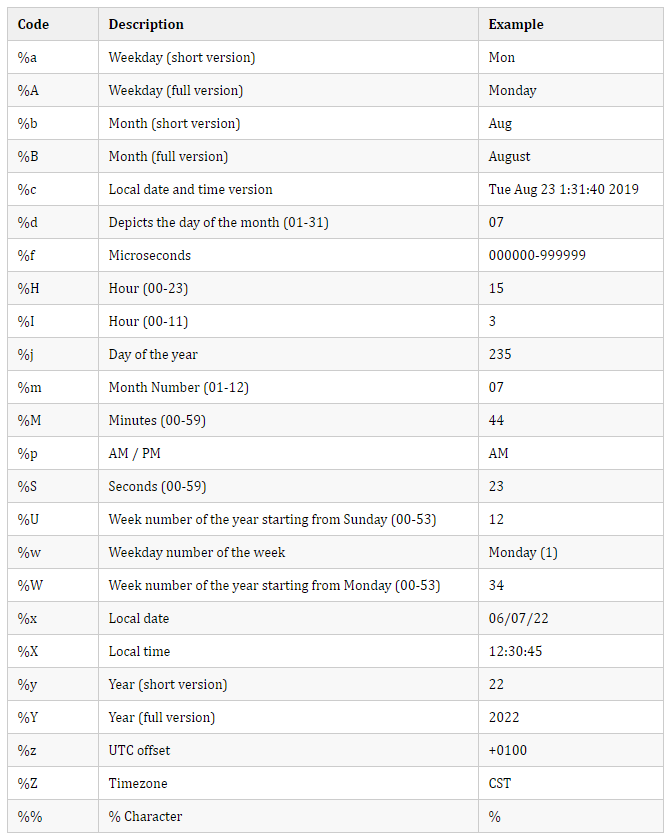
在用示例解释每个函数之前,先看一下所有合法的格式化代码的方式:
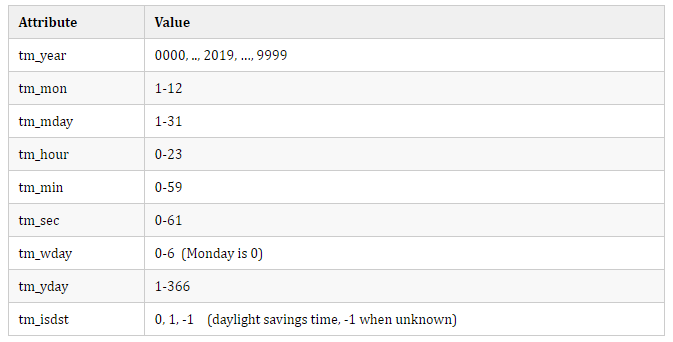
struct_time 类具有以下属性:
datetime 模块
与time模块类似,datetime模块包含处理日期和时间所必需的所有方法。
内置功能:
下表介绍了本模块中的一些重要功能:

calendar模块
该模块定义了很多类型,主要包括:Calendar、TextCalendar、HTMLCalendar,其中 Calendar 是 TextCalendar 和 HTMLCalendar 的基类,这些类有着十分丰富的日历处理方法。
同时ISO 8601标准还规定了 0 和 负数年份。0年指公元前1年, -1年指公元前2年,依此类推。
具体代码:
import math
from datetime import datetime, timedelta, date
import calendar
def get_today_zero_time():
"""
获取当前零点时间
"""
time_now = datetime.now()
zero_time = time_now - timedelta(hours=time_now.hour) - timedelta(minutes=time_now.minute) - timedelta(
seconds=time_now.second) - timedelta(microseconds=time_now.microsecond)
return zero_time
def get_current_hour():
"""
获取当前整点时间
"""
time_now = datetime.now()
time_now_hour = time_now - timedelta(minutes=time_now.minute) - timedelta(seconds=time_now.second) - timedelta(
microseconds=time_now.microsecond)
return time_now_hour
def get_last_five_minutes_time():
"""
获取上一个整五分钟时间
"""
time_now = datetime.now()
mins = math.floor(time_now.minute /5) *5
time_now_hour = time_now - timedelta(minutes=time_now.minute) - timedelta(seconds=time_now.second) - timedelta(
microseconds=time_now.microsecond) + timedelta(minutes=mins)
return time_now_hour
def get_month_start_time():
now = datetime.now().date()
this_month_start = datetime(now.year, now.month, 1)
this_month_end = datetime(now.year, now.month, calendar.monthrange(now.year, now.month)[1])
return this_month_start
def get_month_first_and_last_day(year, month):
# 获取当前月的第一天的星期和当月总天数
weekDay, monthCountDay = calendar.monthrange(year, month)
# 获取当前月份第一天
firstDay = date(year, month, day=1)
# 获取当前月份最后一天
lastDay = date(year, month, day=monthCountDay)
# 返回第一天和最后一天
return firstDay, lastDay
def get_past_month_first_and_last_day():
if date.today().month ==1:
lastMonthFirstDay = date(date.today().year-1, 12, 1)
else:
lastMonthFirstDay = date(date.today().year, date.today().month - 1, 1)
lastMonthLastDay = date(date.today().year, date.today().month, 1) - timedelta(1)
return lastMonthFirstDay, lastMonthLastDay
def get_year_first_and_last_day(now_time):
this_year_start = datetime(now_time.year, 1, 1)
this_year_end = datetime(now_time.year + 1, 1, 1) - timedelta(days=1)
return this_year_start, this_year_end
def get_this_week_start_and_end_day():
today = date.today()
return today - timedelta(days=today.weekday())
def get_past_week_start_and_end_day():
today = date.today()
# threeWeeksAgo_start = today - timedelta(days=today.weekday() + 21)
# threeWeeksAgo_end = today - timedelta(days=today.weekday() + 15)
# twoWeeksAgo_start = today - timedelta(days=today.weekday() + 14)
# twoWeeksAgo_end = today - timedelta(days=today.weekday() + 8)
last_week_start = today - timedelta(days=today.weekday() + 7)
last_week_end = today - timedelta(days=today.weekday() + 1)
return last_week_start, last_week_end
def get_week_start_and_end_day_at_date(q_date):
last_week_start = q_date - timedelta(days=q_date.weekday() + 7)
last_week_end = q_date - timedelta(days=q_date.weekday() + 1)
return last_week_start, last_week_end
if __name__ == "__main__":
print(get_last_five_minutes_time())
print(get_month_start_time())
print(get_today_zero_time() - get_month_start_time())
print(get_month_first_and_last_day(get_today_zero_time().year, get_month_start_time().month))
print(get_past_month_first_and_last_day())
print(get_past_week_start_and_end_day())
参考链接:
http://www.bryh.cn/a/63810.html
2 comments
来学习啦!
杜老师客气啦~~~