Search results
63 results found.
Artificial Intelligence / Reverse Engineering / Internet of Things / Full Stack Developer
63 results found.

github在为支持私有项目之前,很多的代码都是基于bitbucket托管的。整体体验也还算ok。不过有段时间bitbucket服务貌似周期性被墙,尤其是登录跳转,异常的恶心。在bitbucket上托管的代码基本都是非公开的项目,包含各种图片站的爬虫,语音助理等。
Bitbucket 对于个人以及最多具有 5 位用户的小型团队是免费的,并提供无限制的公共和私人存储库。您还可以获得 LFS 的 1 GB 文件存储和 50 分钟的构建时间,以便开始使用 Pipelines。您可以在工作区与所有用户共享构建分钟数和存储。


uptime-kuma是一款开源监控工具,类似于“Uptime Robot和statping”,ui非常简洁美观,支持TCP/PING/HTTP监控等,还支持多语言其中包括中文!
项目:https://github.com/louislam/uptime-kuma

代码自动补全这个功能还是比较需要的,尤其是大项目。在其他模块内定义的数据类型,如果没有代码自动补全写起来太麻烦了。比如django的model中定义的属性,写查询filter的时候,没有代码自动完成,就需要去找各个属性,更恶心的是外键的关联查询直接没有__补全的功能,就得去找对应关系。数据结构复杂了之后这个工作就变成了灾难。
目前使用过的主要有下面几个:
1.kite
Kite 是一家成立于 2014 年的创业公司,主要从事于开发同名的人工智能编程助手,就类似于大家熟悉的 GitHub Copilot。Kite 最初仅支持 Python 和 JavaScript 这两种编程语言,在 2020 年年底,Kite 额外支持了 TypeScript、Java、Go、C、C#、Kotlin 等编程语言,支持的编程语言一下上升到 13 种。Kite 还支持 16 种编辑器 / IDE,其中包括 VS Code、IntelliJ、Vim、Sublime Text 等,在这一点上支持的范围要高于 GitHub Copilot。

代码:
def proxy_get_content_stream(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
return requests.get(url, headers=HEADERS, stream=True, timeout=300)
def save_image_from_url_with_progress(url, cnt):
with closing(proxy_get_content_stream(url)) as response:
chunk_size = 1024 # 单次请求最大值
content_size = int(response.headers['content-length']) # 内容体总大小
data_count = 0
with open(cnt, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_position = (data_count / content_size) * 100
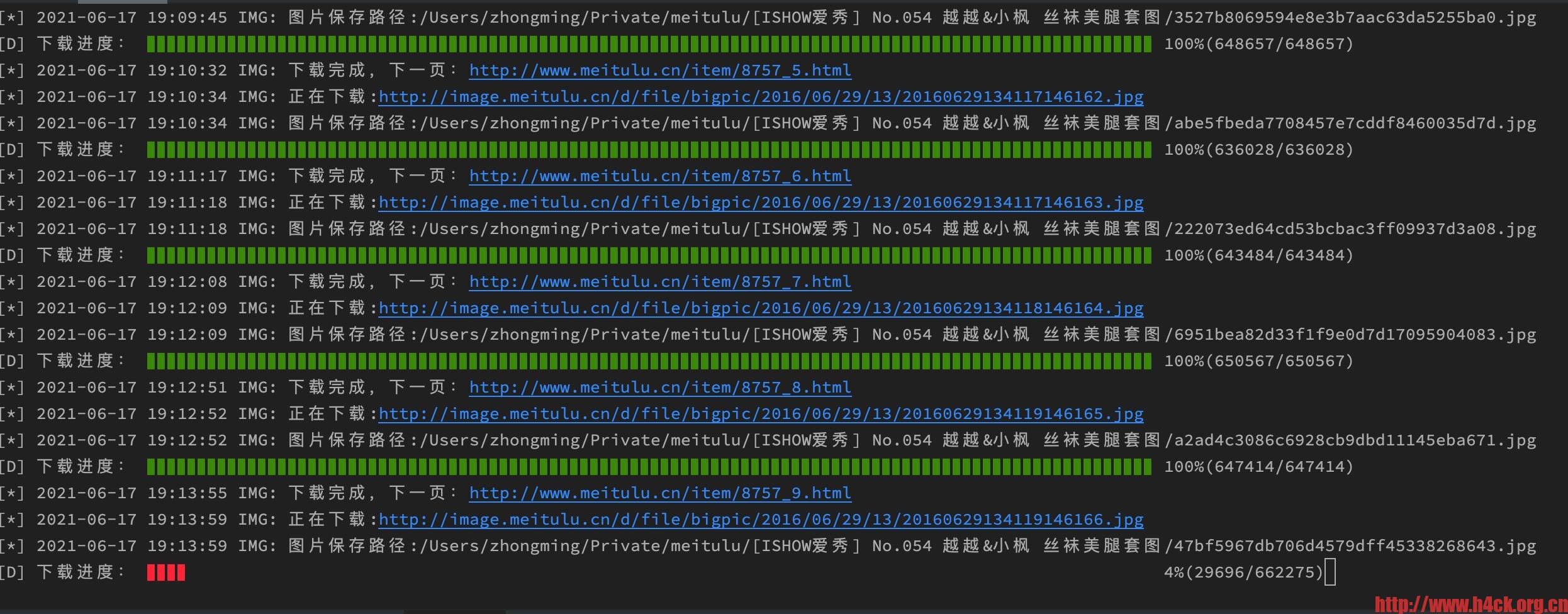
print("\r[D] 下载进度: %s %d%%(%d/%d)" % (int(now_position) * '▊' + (100 - int(now_position)) * ' ',
now_position,
data_count,
content_size,), end=" ")
print('')
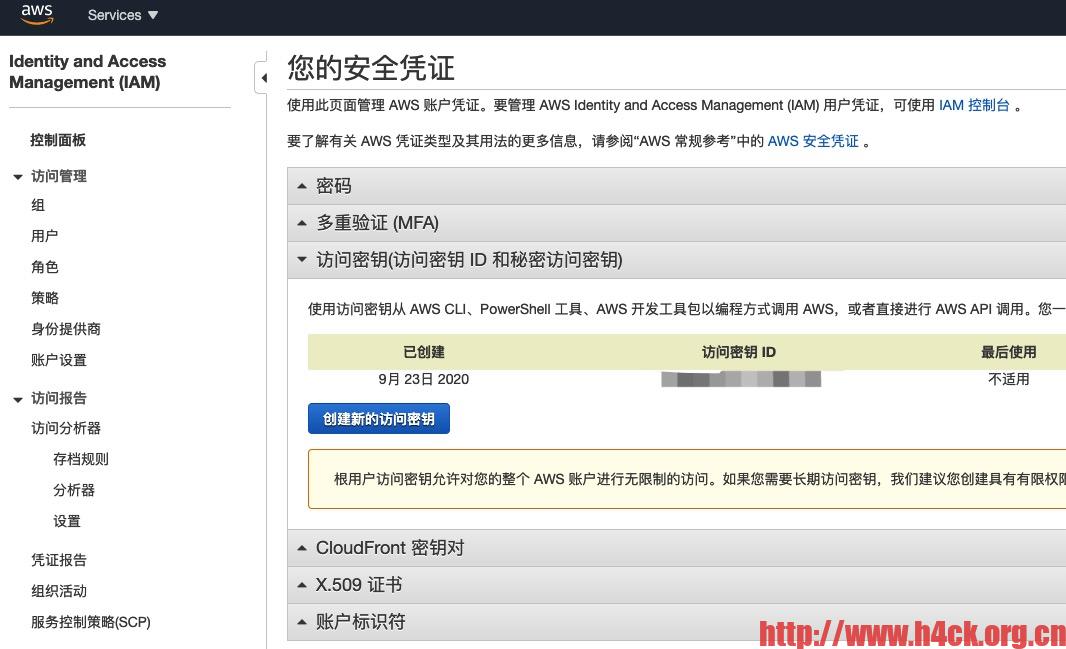
爬虫文件在服务器上爬取数据的时候下载了很多的数据,为了保存这些数据,给这些数据做个备份于是就想把文件传到s3存储上。其实要上传文件也比较简单,通过awscli命令行工具即可上传。首选需要去aws的后台创建访问安全凭证。点击用户名,选择访问密钥,创建新的访问密钥,下载之后是一个csv文件包含AWSAccessKeyId和AWSSecretKey
在服务器上安装awscli,执行
sudo apt install awscli
安装aws命令行工具。
安装完成之后执行
aws configure
进行配置,输入key和secret即可:

最后两项可以留空。
'''
--------------------------------------------------------------------------------
福利数据解析
基础数据分析,标题分词,词频统计
-----------------------------------
by:obaby
email: root@obaby.org.cn
blog:http://www.h4ck.org.cn
===================================
参考链接:https://sparkbyexamples.com/pyspark/select-columns-from-pyspark-dataframe/
-------------------------------------------------------------------------------
'''
import jieba
# 通过spark read csv格式文件,从csv header解析数据结构
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie.csv")
# 数据格式
csv.printSchema()
root
|-- id: string (nullable = true)
|-- create: string (nullable = true)
|-- update: string (nullable = true)
|-- name: string (nullable = true)
|-- describe: string (nullable = true)
|-- source_id: string (nullable = true)
|-- publish_time: string (nullable = true)
|-- play_count: string (nullable = true)
|-- good_count: string (nullable = true)
|-- bad_count: string (nullable = true)
|-- link_count: string (nullable = true)
|-- comment_count: string (nullable = true)
|-- designation: string (nullable = true)
|-- category_id: string (nullable = true)
|-- porn_site_id: string (nullable = true)
|-- uploader_id: string (nullable = true)
|-- producer: string (nullable = true)