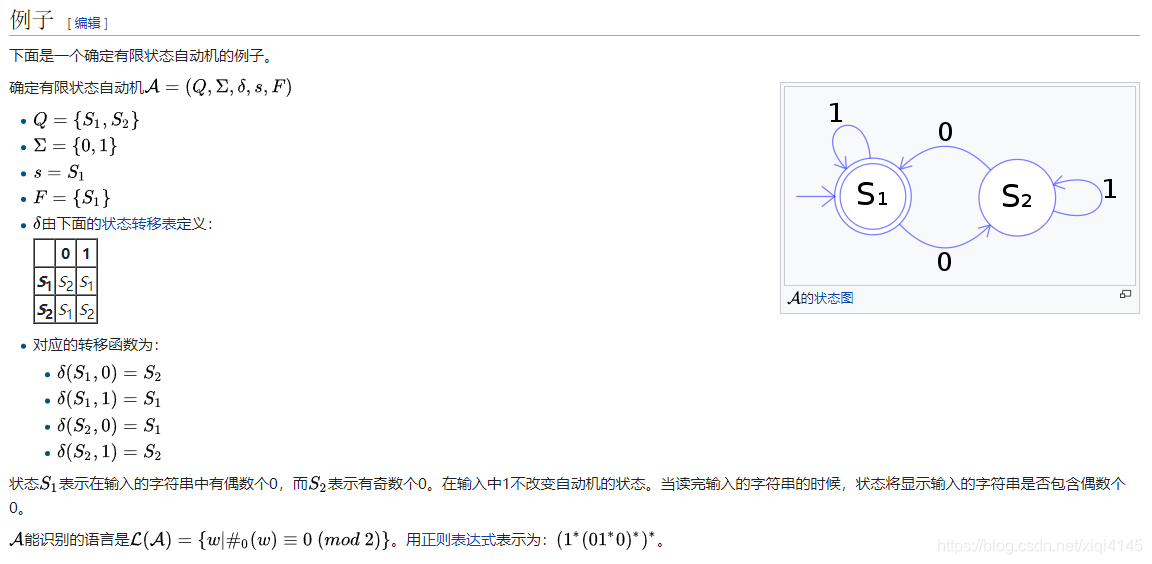
在计算理论中,确定有限状态自动机或确定有限自动机(英语:deterministic finite automaton, DFA)是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表{\displaystyle \Sigma }Σ的字符,它都能根据事先给定的转移函数转移到下一个状态
DFA算法
DFA((Deterministic Finite automation))确定性的有穷状态自动机: 从一个状态输入一个字符集合能到达下一个确定的状态。如图:

dfa_1.png
如上图当AB状态输入a得到状态aB,状态aB输入b得到状态ab; 状态AB输入b得到状态Ab,状态Ab输入a得到状态ab。
利用DFA匹配关键词
上面开始的几个关键词匹配可以用下图来表示:

dfa_2.png
0是开始状态,输入日、本、人会最终到达结束状态5,输入日、本、鬼、子最终到达结束状态8,输入中、国、人到达结束状态7。
以上的状态图输入字符类似树形结构,空心状态表示未结束状态(isEnd=false), 蓝色环形状态表示结束状态(isEnd=true)。用HashMap维护这个字典关系.
代码(Python3 非原创代码):
from collections import defaultdict
import re
__all__ = ['NaiveFilter', 'BSFilter', 'DFAFilter']
__author__ = 'observer'
__update__ = 'obaby@mars https://www.h4ck.org.cn'
__update_date__ = '2019.11.27'
class NaiveFilter():
'''Filter Messages from keywords
very simple filter implementation
>>> f = NaiveFilter()
>>> f.add("sexy")
>>> f.filter("hello sexy baby")
hello **** baby
'''
def __init__(self):
self.keywords = set([])
def parse(self, path):
for keyword in open(path):
self.keywords.add(keyword.strip().decode('utf-8').lower())
def filter(self, message, repl="*"):
message = message.lower()
for kw in self.keywords:
message = message.replace(kw, repl)
return message
class BSFilter:
'''Filter Messages from keywords
Use Back Sorted Mapping to reduce replacement times
>>> f = BSFilter()
>>> f.add("sexy")
>>> f.filter("hello sexy baby")
hello **** baby
'''
def __init__(self):
self.keywords = []
self.kwsets = set([])
self.bsdict = defaultdict(set)
self.pat_en = re.compile(r'^[0-9a-zA-Z]+$') # english phrase or not
def add(self, keyword):
if not isinstance(keyword, str):
keyword = keyword.decode('utf-8')
keyword = keyword.lower()
if keyword not in self.kwsets:
self.keywords.append(keyword)
self.kwsets.add(keyword)
index = len(self.keywords) - 1
for word in keyword.split():
if self.pat_en.search(word):
self.bsdict[word].add(index)
else:
for char in word:
self.bsdict[char].add(index)
def parse(self, path):
with open(path, "r") as f:
for keyword in f:
self.add(keyword.strip())
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = message.decode('utf-8')
message = message.lower()
for word in message.split():
if self.pat_en.search(word):
for index in self.bsdict[word]:
message = message.replace(self.keywords[index], repl)
else:
for char in word:
for index in self.bsdict[char]:
message = message.replace(self.keywords[index], repl)
return message
class DFAFilter():
'''Filter Messages from keywords
Use DFA to keep algorithm perform constantly
>>> f = DFAFilter()
>>> f.add("sexy")
>>> f.filter("hello sexy baby")
hello **** baby
'''
def __init__(self):
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
if not isinstance(keyword, str):
keyword = keyword.decode('utf-8')
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
with open(path, encoding='UTF-8') as f:
for keyword in f:
self.add(keyword.strip())
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = message.decode('utf-8')
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
return ''.join(ret)
def is_contain_sensi_key_word(self, message):
repl = '_-__-'
dest_string = self.filter(message=message, repl=repl)
if repl in dest_string:
return True
return False
def test_first_character():
gfw = DFAFilter()
gfw.add("1989年")
assert gfw.filter("1989", "*") == "1989"
if __name__ == "__main__":
# gfw = NaiveFilter()
# gfw = BSFilter()
gfw = DFAFilter()
gfw.parse("keywords")
import time
t = time.process_time()
print(gfw.filter("法 我操操操", "*"))
print(gfw.filter("针孔摄像机 我操操操", "*"))
print(gfw.filter("传世私服 我操操操", "*"))
print('Cost is %6.6f' % (time.process_time() - t))
print(gfw.is_contain_sensi_key_word('习大大'))
test_first_character()
Github: https://github.com/obaby/dfa-python-filter
参考链接:
https://www.jianshu.com/p/e58a148eecc5
https://blog.csdn.net/u013421629/article/details/83178970
https://www.jianshu.com/p/c0c7667dc6c5
https://blog.csdn.net/xiqi4145/article/details/84313809